
Dataset with 10K points
Denoising process for 10K data points
The performance of diffusion models degrades significantly in the few-shot setting. The model is not be able to learn the data manifold and generates samples that are far from the data manifold.

Dataset with 20 points
Denoising process for 20 data points
Generative Adversarial Network
Implicit Maximum Likelihood Estimation is an alternative to the GAN objective and has shown promising results in addressing mode collapse.
GAN training: mode collapse
IMLE training
The Misalignment Issue
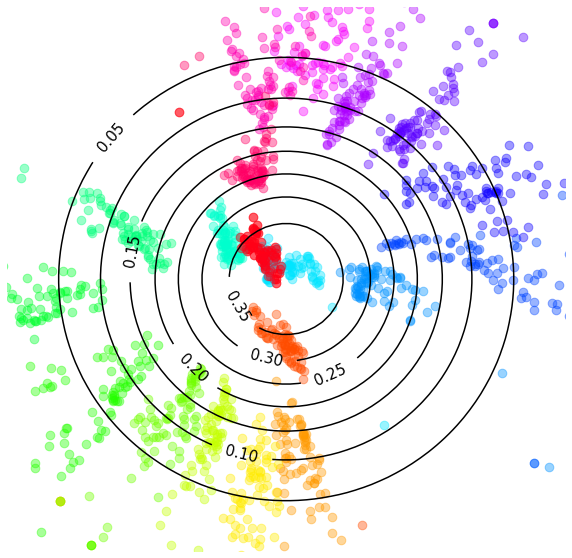
Latent codes selected by IMLE objective during training
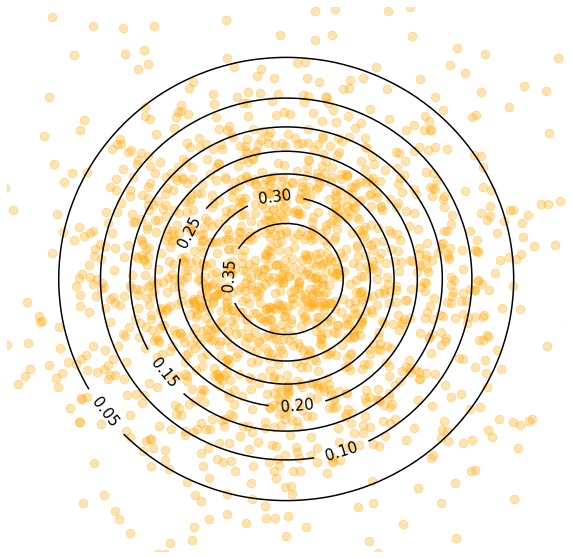
Latent codes sampled at test time
Since at test time we sample from the same standard normal distribution, these unsupervised segments in the latent space have arbitrary outputs, which result in bad samples.
Methodology
Since we reject samples that are too close to the data points, we call our method Rejection Sampling IMLE (RS-IMLE).
Note: 🟩 denotes data points and 🟠 denote samples from the model.

IMLE
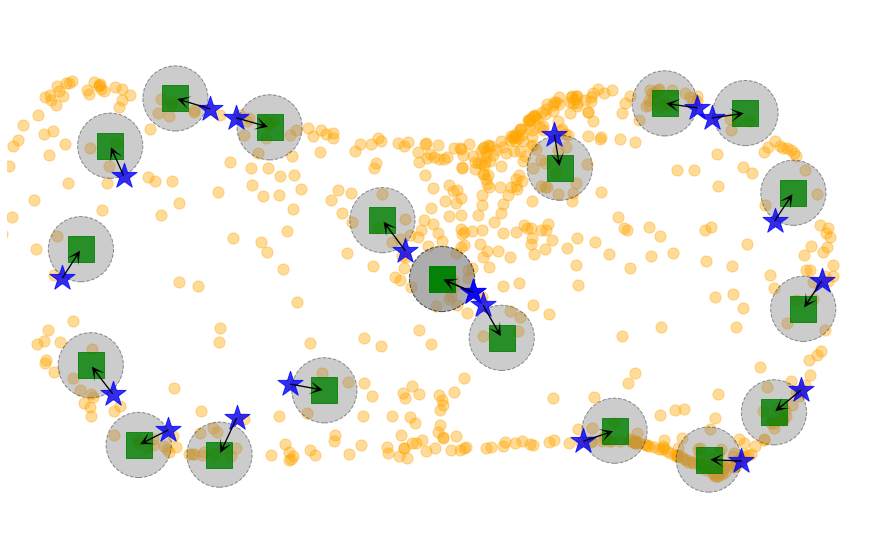
RS-IMLE
IMLE
RS-IMLE
Latent codes selected by IMLE objective during training
Latent codes selected by RS-IMLE objective during training
Frechet Inception Distance
We present the FID scores computed for all the datasets across different methods. Lower FID scores indicates that the distribution of generated images is closer to the distribution of real images.
Our method performs significantly better compared to baselines. We report an average improvement of 45.9% over the best baseline.
| Dataset | FastGAN | FakeCLR | FreGAN | ReGAN | AdaIMLE | RS-IMLE |
|---|---|---|---|---|---|---|
| Obama | 41.1 | 29.9 | 33.4 | 45.7 | 25.0 | 14 |
| Grumpy Cat | 26.6 | 20.6 | 24.9 | 27.3 | 19.1 | 11.5 |
| Panda | 10.0 | 8.8 | 9.0 | 12.6 | 7.6 | 3.5 |
| FFHQ-100 | 54.2 | 62.1 | 50.5 | 87.4 | 33.2 | 12.9 |
| Cat | 35.1 | 27.4 | 31.0 | 42.1 | 24.9 | 15.9 |
| Dog | 50.7 | 44.4 | 47.9 | 57.2 | 43.0 | 23.1 |
| Anime | 69.8 | 77.7 | 59.8 | 110.8 | 65.8 | 35.8 |
| Skulls | 109.6 | 106.5 | 163.3 | 130.7 | 81.9 | 51.1 |
| Shells | 120.9 | 148.4 | 169.3 | 236.1 | 108.5 | 55.4 |
Visual Recall Test
First column is the query image from the dataset.
Subsequent columns are the samples produced by different methods that are closest to the query image in LPIPS feature space.
Note that the samples from our method are:
- Realistic (indicating high precision)
- Closer to the query (indicating high recall)
- Diverse (indicating that the model is not overfitting)

Anime dataset

Cat dataset

FFHQ-100 dataset
You can find more examples in the main paper and the supplementary material.
Video Presentation
BibTeX
@inproceedings{vashist2024rejectionsamplingimledesigning,
title = {Rejection Sampling IMLE: Designing Priors for Better Few-Shot Image Synthesis},
author = {Chirag Vashist and Shichong Peng and Ke Li},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2024}
}